대형 언어 모델
본 서비스가 제공하는 내용 및 자료가 사실임을 보증하지 않습니다. 시스템은 언제나 실수를 할 수 있습니다. 중요한 의사결정 및 법리적 해석, 금전적 의사결정에 사용하지 마십시오.
대형 언어 모델(Large Language Model, LLM)은 수많은 매개변수(Parameter)를 보유한 인공 신경망으로 구성된 언어 모델이다. 일반적으로 수십억 개 이상의 가중치를 가지며, 레이블링되지 않은 방대한 양의 텍스트 데이터를 자기 지도 학습이나 반자기지도학습 방식으로 훈련한다. 2018년경부터 본격적으로 등장하여 특정 작업에 특화된 기존의 지도 학습 패러다임에서 벗어나 자연어 처리 연구의 중심축이 되었다. 생성형 인공지능과 AI 챗봇 기술을 가능하게 하는 핵심 요소로 평가받는다.
개요 및 특징
대형 언어 모델은 딥러닝 기술을 활용하여 방대한 데이터 세트에서 학습된 여러 신경망 계층으로 구성된다. 이 모델들은 기존의 N-gram 언어 모델이나 순환 신경망(RNN)보다 훨씬 더 많은 매개변수를 포함하며, 이를 통해 더 넓은 문맥을 파악할 수 있다. 인공지능이 문장 내에서 다음에 올 토큰이나 토큰의 시퀀스를 예측하는 방식으로 작동하며, 여기서 토큰은 단어, 하위 단어, 또는 단일 문자가 될 수 있다.
기존 검색 엔진이 키워드 일치 방식을 사용하는 것과 달리, 대형 언어 모델은 깊은 맥락과 뉘앙스, 추론을 포착하는 데 탁월하다. 이는 인간이 기술과 상호작용하는 방식을 근본적으로 변화시키는 계기가 되었다.
기술적 구조
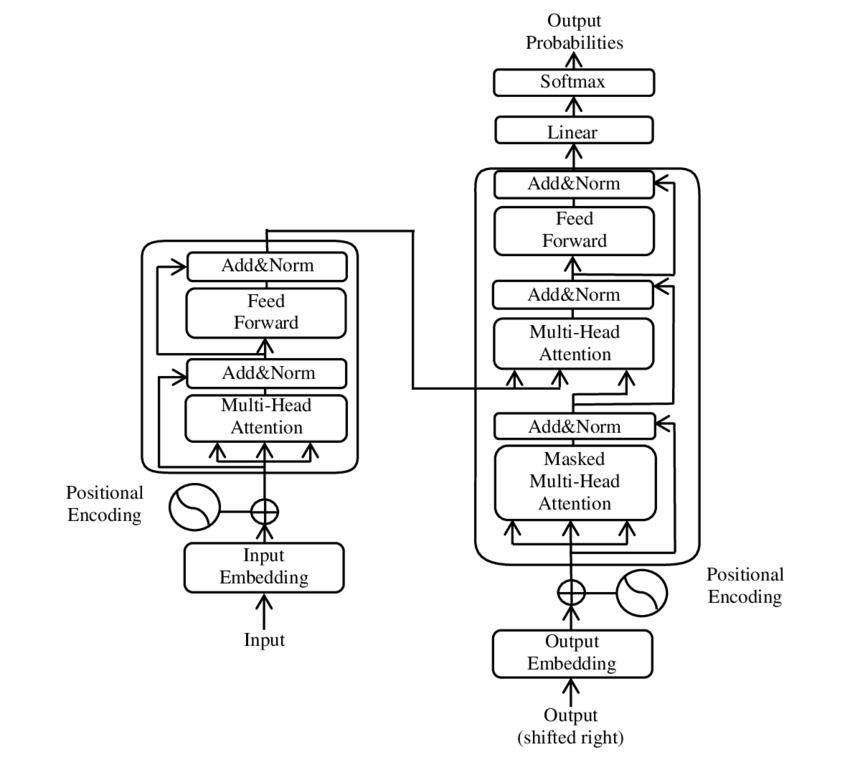
대형 언어 모델 구축에 가장 널리 사용되는 아키텍처는 **트랜스포머(Transformer)**이다. 2017년 구글이 발표한 논문 'Attention Is All You Need'에서 처음 소개된 이 구조는 다음과 같은 핵심 기술을 포함한다.
- 셀프 어텐션(Self-attention): 입력 데이터를 처리할 때 데이터의 각 부분에 가중치를 할당하여, 맥락상 중요한 부분에 집중하게 한다.
- 위치 인코딩(Positional Encoding): 시퀀스 내에서 입력 데이터가 나타나는 순서 정보를 포함하여, 단어가 비순차적으로 입력되어도 문맥을 파악할 수 있게 한다.
- 계층 구조: 트랜스포머 블록을 여러 층으로 쌓아 올려 모델의 깊이를 더하며, 각 층은 피드포워드층, 정규화층 등으로 구성된다.
학습 및 라이프사이클
대형 언어 모델의 개발 과정은 크게 데이터 준비, 학습, 미세 조정 단계로 나뉜다.
- 데이터 준비: 원시 데이터를 수집하고 중복이나 오류를 제거하는 정제 과정을 거친다. 이후 모델이 이해할 수 있는 단위인 토큰으로 나누는 토큰화 작업을 수행한다.
- 사전 학습(Pre-training): 자기 지도 학습을 통해 수천억 개의 단어로 구성된 데이터 세트에서 언어의 통계적 패턴과 지식을 습득한다.
- 미세 조정(Fine-tuning): 사전 학습된 모델을 특정 작업이나 도메인에 맞게 추가로 훈련시켜 정확도를 높인다.
- 추론: 학습된 모델이 새로운 입력(프롬프트)에 대해 적절한 응답을 생성하는 단계이다.
주요 모델 사례
다양한 기업과 연구소에서 대형 언어 모델을 개발하여 공개하고 있다.
| 모델명 | 개발사 | 특징 |
|---|---|---|
| GPT-3 | 오픈AI | 1,750억 개의 매개변수를 보유하여 초기 LLM 열풍을 주도함 |
| LLaMA | 메타 AI | 연구 커뮤니티에 모델 가중치를 공개하여 접근성을 높임 |
| 제미나이(Gemini) | 구글 | 멀티모달 능력을 갖춘 인공지능 모델 시리즈 |
| 젬마(Gemma) | 구글 | 매개변수 규모에 따라 다양한 버전으로 나뉘는 개방형 경량 모델 |
산업적 영향 및 한계
대형 언어 모델은 생성형 인공지능의 원동력이 되었으며 기사 요약, 코드 디버깅, 법률 조항 초안 작성 등 텍스트 해석과 관련된 다양한 분야에 적용된다. 특히 오픈소스 라이선스를 채택한 모델들은 상업적 이용이 자유로워 기업들이 독자적인 AI 에이전트를 구축하는 데 활용된다.
그러나 학습 데이터의 편향성이나 부정확한 정보를 생성하는 문제, 안전성 및 정렬(Alignment) 이슈 등이 한계로 지적된다. 이를 해결하기 위해 모델의 추론 능력과 사실 정확도를 측정하는 벤치마크 평가가 지속적으로 이루어지고 있다.