DeepSeek V4
본 서비스가 제공하는 내용 및 자료가 사실임을 보증하지 않습니다. 시스템은 언제나 실수를 할 수 있습니다. 중요한 의사결정 및 법리적 해석, 금전적 의사결정에 사용하지 마십시오.
DeepSeek V4는 중국의 인공지능 기업 딥시크(DeepSeek-AI)가 2026년 4월 24일 프리뷰(Preview) 버전으로 공개한 4세대 대규모 언어 모델(LLM)이다. Mixture-of-Experts(MoE) 아키텍처를 기반으로 설계되었으며, 최대 100만 토큰의 컨텍스트 길이를 지원하는 것이 핵심 특징이다. DeepSeek-V4-Pro와 DeepSeek-V4-Flash 두 가지 주요 변형 모델로 구성되며, 오픈 웨이트(Open-weight) 형태로 MIT 라이선스에 따라 공개되었다.
개요
DeepSeek V4는 기존 DeepSeek V3의 후속 모델로, 대규모 데이터를 처리하면서도 추론 비용을 획기적으로 낮추는 데 집중한 모델이다. 2026년 4월 24일 기술 보고서와 함께 모델 가중치가 허깅페이스(Hugging Face)를 통해 공개되었다. 100만 토큰에 달하는 긴 컨텍스트를 실용적인 비용으로 처리할 수 있도록 설계되었으며, 코딩과 추론 능력에서 세계 최고 수준의 성능을 목표로 한다.
모델 구성
DeepSeek V4 시리즈는 성능 중심의 Pro 모델과 효율성 중심의 Flash 모델로 나뉜다.
| 모델명 | 총 파라미터 | 활성 파라미터 | 특징 |
|---|---|---|---|
| DeepSeek-V4-Pro | 1.6T | 49B | 최상위 성능, 33T 토큰 학습 |
| DeepSeek-V4-Flash | 284B | 13B | 고속 추론, 경제적 운영 |
두 모델 모두 100만 토큰의 컨텍스트 길이를 기본으로 지원하며, Pro 모델은 최대 384K 토큰의 출력을 생성할 수 있다.
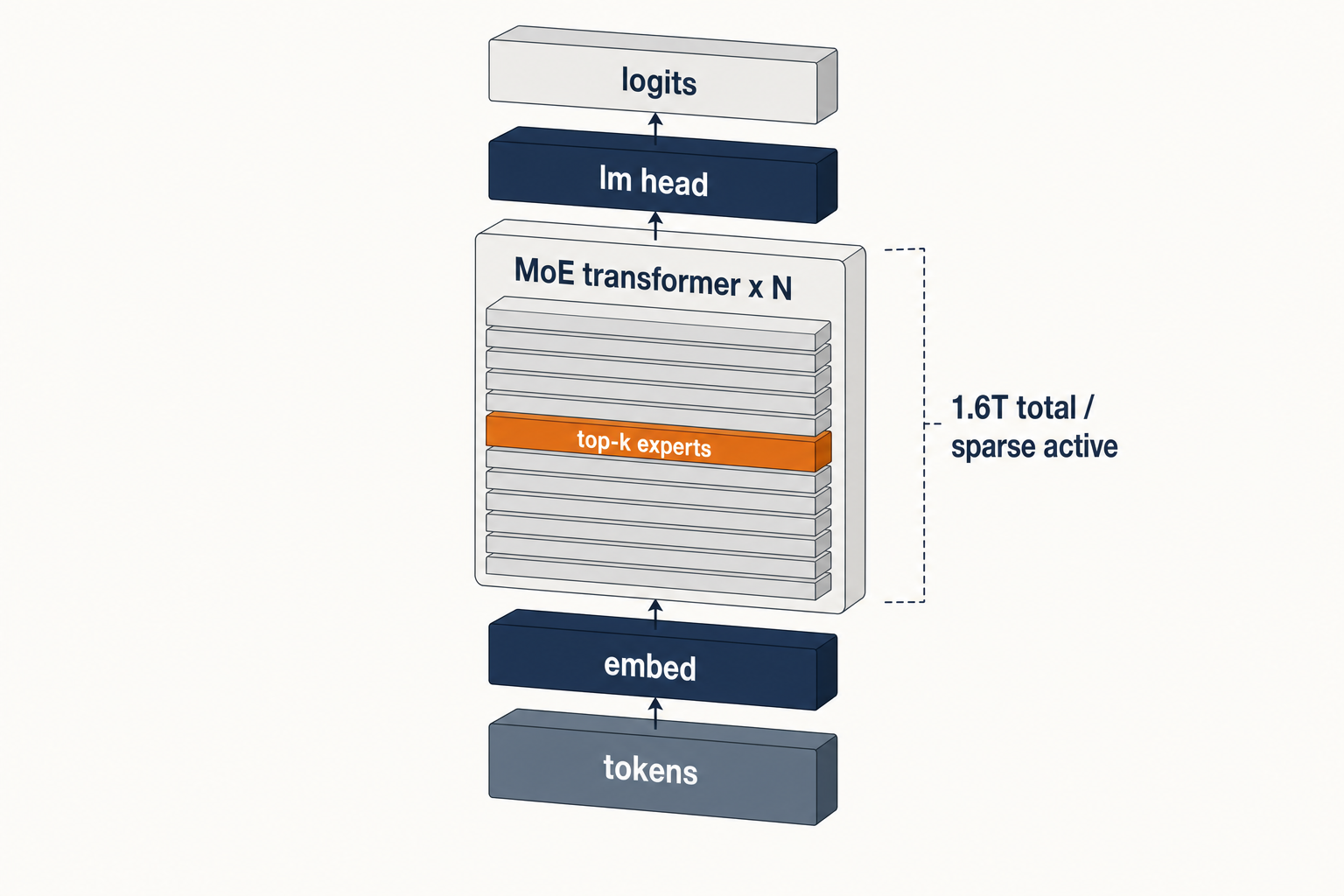
기술적 특징
DeepSeek V4는 긴 컨텍스트 처리와 학습 효율을 위해 여러 혁신적인 기술을 도입하였다.
- 하이브리드 어텐션(Hybrid Attention): 압축 희소 어텐션(Compressed Sparse Attention, CSA)과 고압축 어텐션(Heavily Compressed Attention, HCA)을 결합하여 추론 시 메모리 점유율을 낮췄다.
- Muon 옵티마이저: 학습 효율을 극대화하기 위해 도입된 새로운 최적화 알고리즘이다.
- mHC(manifold-constrained): 잔차 연결(Residual Connection)을 매니폴드 위에 가두어 모델의 안정성을 높이는 설계 축을 적용하였다.
- KV 캐시 최적화: V3.2 대비 KV 캐시 사용량을 약 10% 수준으로 절감하여 긴 문맥에서도 효율적인 추론이 가능하다.
성능 및 벤치마크
DeepSeek-V4-Pro는 다양한 벤치마크에서 폐쇄형 모델과 대등한 성능을 보였다. 특히 에이전트 코딩(Agentic Coding) 분야에서 오픈소스 모델 중 최고 수준을 기록하였으며, Codeforces 레이팅은 3206점에 달한다. 세계 지식(World Knowledge) 부문에서는 Gemini-3.1-Pro에 이어 두 번째로 높은 점수를 기록하며 공개된 모든 오픈 모델 중 선두를 차지하였다. 추론(Reasoning) 능력 또한 세계 최고 수준으로 평가받는다.
배포 및 이용
DeepSeek V4는 공식 웹사이트(chat.deepseek.com)에서 엑스퍼트 모드(Expert Mode) 또는 인스턴트 모드(Instant Mode)를 통해 이용할 수 있다. API 서비스도 출시와 동시에 업데이트되었으며, NVIDIA의 Blackwell GPU 가속 엔드포인트를 통한 지원이 발표되었다. 긴 컨텍스트를 활용한 문서 분석, 복잡한 코드 생성, 에이전트 AI 워크플로 등에 최적화되어 있다.